- Bamba Herberholz
- Ndiaye
- Hesso
- Kokoreff
- Djamen
- Jarosz
- Chafei
- Durasi
- Gao
- Knickenberg
- Herbig
- Grünig
- Kücük
- Taeb
- Kocak
- Ganjimansesh
- Grcic
- Arslan
- Maghsoudloo
- Herbig
- Al Altrash
- Bohr
- Örnek
- Hoffmann
- Georgiev
- Nurgün
- Enge
- Langenbrink
- Hermann
- Dunklau
- Boerner
- Cornelius
- Strzebinczyk
- Lohmann
- Böhmer
- Pelka
- Mallaoui
- Kocherscheidt
- Pete
Erstbetreuer: Prof. Dr. Ursula Oesing
Zweitbetreuer: Dipl. Ing. (FH) Stefan Jonker
Thema:
Implementierung und Integration von Varianten des IPO-Algorithmus in ein Unit Testing Framework sowie Untersuchung der Testbarkeit ausgewählter Anwendungen.
Einleitung
Dem Verifizieren und Validieren von Software kommt in der heutigen Welt eine immer wichtigere Rolle zu, denn unser Leben ist immer mehr von Software anhängig. Gleichzeitig nimmt auch der Anteil komplexer Systeme zu, die untereinander oft Abhängigkeiten besitzen: Viele Faktoren beeinflussen die Performance und Korrektheit. Kombinatorisches Testen (engl. Combinatorial Testing (CT)), oder Kombinatorisches Interaction Testing (CIT), ist ein Ansatz diese Systeme zu überprüfen.
Das Verhalten von solchen Systemen wechselt, je nach dem, was die Faktoren für Werte annehmen. Beispielsweise können die Komponenten eines Softwaresystems unterschiedlich konfiguriert werden. Es ist häufig der Fall, dass es nicht ausreicht, diese Faktoren isoliert zu betrachten, sondern dies in Kombination untereinander getan werden muss: CT tut dies in einer effektiven Art und Weise.
Beispiel
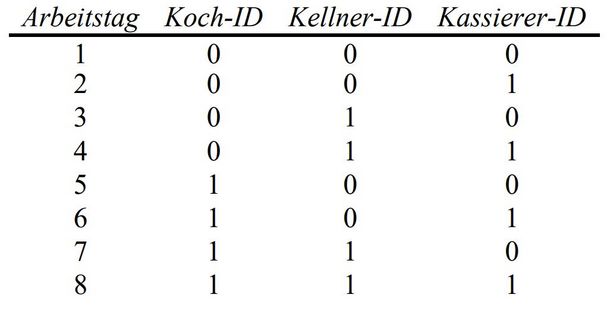
Die Besetzung eines neuen Restaurants besteht aus einem Koch, einem Kellner und einem Kassierer. In jeder dieser Positionen gibt es zwei Angestellte, die jeweils in Teilzeit arbeiten: Das heißt, je Arbeitstag wird jede der drei Positionen mit einem der beiden Angestellten besetzt, die auf dieser Position arbeiten können. Der Inhaber des Restaurants weiß, dass es möglich ist, dass sich zwei Leute nicht verstehen: Beispielsweise kann es sein, dass sich einer der beiden Köche nicht mit einem der beiden Kellner versteht. Oder es kann sein, dass sich alle beiden Kellner mit keinem der Kassierer vertragen. Wenn sich zwei Leute nicht verstehen, fällt dies bereits beim ersten gemeinsamen Arbeitstag auf. Der Inhaber würde gerne alle diese Personenpaare identifizieren und für sie ein Teambuilding-Seminar buchen. Damit er sicher sein kann, dass er alle Personenpaare identifiziert hat, muss also jede Person einmal mit jeder anderen Person am gleichen Tag zusammengearbeitet haben – abgesehen von dem Angestellten, der auf derselben Position arbeitet. Es wird eine Besetzung bestimmt, mit der alle paarweisen Kombinationen abgedeckt werden.
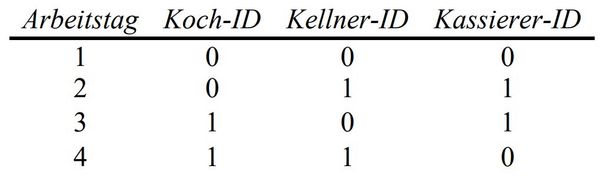
Nun hat der Inhaber aber von einem Freund gehört, dass es bei frühen Buchungen zum Teambuilding-Seminar Rabatt gibt. Der Inhaber überprüft daher, ob es nicht möglich ist alle betroffenen Personenpaare in weniger Arbeitstagen als bisher zu identifizieren – in so wenig wie möglich. Nach einigen Überlegungen kommt er zu dieser Neuaufstellung, mit der er zufrieden ist.
Wenn sich zum Beispiel der Koch mit Koch-ID 0 sich nicht mit einem der beiden Kellner oder Kassierer verstehen würde, so würde dies spätestens an Tag 2 auffallen: Am ersten Tag arbeitet er mit dem Kellner zusammen, der die Kellner-ID 0 hat und er arbeitet mit dem Kassierer zusammen, der die Kassierer-ID 0 hat. Am zweiten Tag arbeitet mit dem Kellner zusammen, der die Kellner-ID 1 hat und er arbeitet mit dem Kassierer zusammen, der die Kassierer-ID 1 hat. Und wenn sich möglicherweise der Koch mit der ID 1 nicht mit einem der Kellner oder Kassierer versteht, so würde dies spätestens an Tag 4 auffallen. Hinweis: Mit Inhaber, Koch, Kellner und Kassierer sind in gleicher Weise Inhaberinnen, Köchinnen, Kellnerinnen und Kassiererinnen gemeint.
Motivation
KBUnit ist ein Tool, mit dem es möglich ist, als Auftraggeber eines Softwareprojekts ohne Programmierkenntnisse die in Auftrag gegebene Anwendung selbst testen zu können. Dazu werden vom Entwickler die definierten Unit-Tests an den Wissensträger weitergeleitet, der diese im Anschluss über eine Java-Desktopanwendung mit eigenen Parameterwerten belegen kann. Außerdem besitzt KBUnit die Funktionalität Testfälle automatisch generieren zu lassen: dazu werden für jeden der Parameter die Werte bestimmt, die der Parameter annehmen kann. Darüber hinaus werden jedem Parameter automatisch ungültige Werte und gegebenenfalls Grenzwerte hinzugefügt, die automatisch ermittelt werden. Vor Beginn dieser Arbeit war es lediglich möglich eine full-factorial (exhaustive) Testsuite aus den validen Parameterwerten zu generieren: wie bereits mit den Beispielen aus dem ersten Kapitel deutlich gemacht worden ist, kann dies schnell zu einer sehr hohen Anzahl an Testfällen führen, was ein Problem sein kann, denn neben der eventuell erforderlichen Belegung eines Ergebnisparameters verbraucht die Ausführung eines Testfalls auch immer Ressourcen verschiedener Art, die nur begrenzt zu Verfügung stehen: Zeit und Rechenleistung. Darüber hinaus können weitere Kosten jeglicher Form anfallen – wie zum Beispiel Geld für die Benutzung von realer oder virtueller Testinfrastruktur. Durch das sparsity-of-effects principle wird beschrieben, dass an einem Fehler, der in einem System auftritt, meistens nur wenige Parameter beteiligt sind: dies motiviert das Vorgehen, dass bei der Generierung einer Testsuite jetzt nur noch deutlich weniger Testfälle benötigt werden, da nicht mehr alle Werte von allen Parametern miteinander kombiniert werden müssen, sondern nur noch alle Werte von jeweils einer bestimmten Anzahl an Parametern – dies ist auch als n-weises Testen bekannt. Daher werden Varianten des IPO-Algorithmus untersucht und in KBUnit implementiert.
Theoretische Hintergründe
Ein Covering Array (CA) ist ein mathematisches Objekt, welches gerne für CT eingesetzt wird. Ein CA(N; t, k, v) ist eine N xk Matrix, wobei N für die Anzahl an Zeilen steht und k für die Anzahl der Spalten. Die Einträge der Matrix stammen aus einer Menge von v ganzen Zahlen v = 0, … , (v - 1). Die entscheidende Eigenschaft eines CA – auch als t-covering property bekannt – ist die Tatsache, dass jede N xt Untermatrix alle möglichen v t Wertekombinationen mindestens λ–mal enthalten.
Entgegen vieler anderen Algorithmen, die Zeile für Zeile (Test für Test) vorgehen, ist die Idee beim In-Parameter-Order (IPO) Algorithmus, das CA Spalte für Spalte (Parameter für Parameter) zu generieren: Je Schritt wird ein CA(N; t, k, v) zu einem CA(N + N'; t, k + 1, v) erweitert. Dies hat den Vorteil, dass wenn wir von einem CA mit (k - 1) Spalten zu einem CA mit k Spalten übergehen wollen, wir nur ( k - 1 t - 1 ) * vt Interaktionen abdecken müssen, denn die neue Spalte k ist im jedem t-Tuple enthalten.
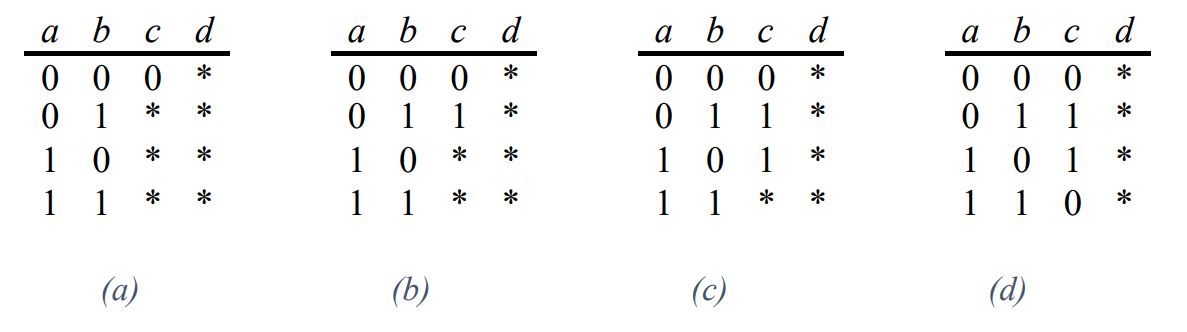
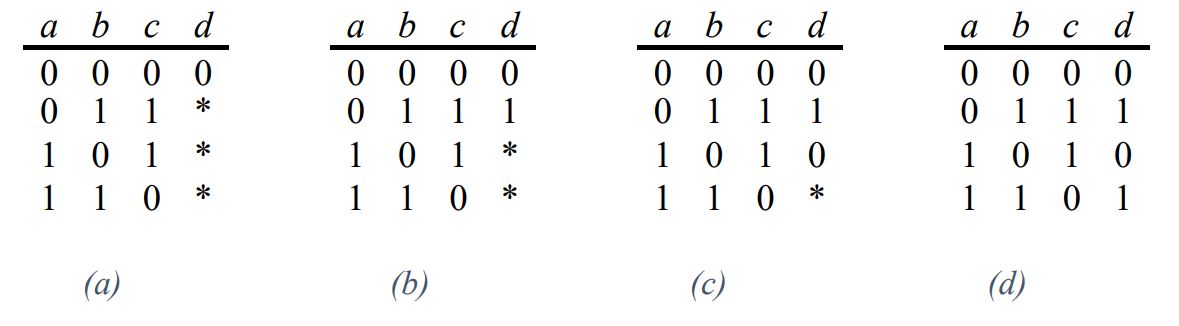
Nachdem in Tabelle 1 das CA, das zu diesem Zeitpunkt aus vier Zeilen bestand, um die Spalte c horizontal erweitert worden ist, waren alle Tupel zwischen den Werten (0 und 1) der Parameter a, b und c bereits erfolgreich abgedeckt. Das bedeutet, dass hier keine vertikale Erweiterung mehr notwendig war. In Tabelle 2 wird das CA, das zuvor um die Spalte c erweitert wurde, um die Spalte d horizontal erweitert: in diesem Fall konnten allein durch das Eintragen eines Wertes in Spalte d der bereits generierten Zeilen noch nicht alle Tupel abgedeckt werden, weshalb die vertikale Erweiterung durchgeführt werden muss.

Aufgrund der Tatsache, dass sich in den ersten vier Zeilen keine don’t-care Werte (mit * als Platzhalter markiert) befinden ist klar, dass, um neue Tupel abdecken zu können, dem CA mindestens eine neue Zeile hinzugefügt werden muss. Bei den beiden fehlenden Tupeln handelt es sich jeweils um Interaktionen zwischen denselben zwei Parametern (b und d), was dazu führt, dass diese Tupel nicht in einem einzigen Test abgedeckt werden können. Die Werte in den Spalten a und c sind jeweils mit don’t-care Werten belegt, da alle zugehörigen Tupel bereits in den vorherigen Zeilen zu finden sind und eine Belegung mit einem richtigen Wert daher kein Unterschied machen würde.