- Studentische Projekte zum EffMi Haus: Nachhaltige Gebäudetechnik
- Drobix: interdisziplinäres Studentenprojekt
- Tischtennis-Ballwurfmaschine: Masterarbeit Mechatronik
- Treppensteigendes Raupenfahrzeug: Bachelorarbeit Mechatronik
- Smartphone-Steuerung für Pokerchips: Interdisziplinäres Projekt
- Entwicklung eines RC-Rettungsboots: CAE-Projekt Mechatronik
- Klassifikation von Bremsgeräuschen: KI & Maschinelles Lernen
- Momentmessung an einem Lenksystem: Abschlussarbeit Mechatronik
- Vortrainierte Tiefenschätzung: Bachelorarbeit Technische Informatik
- Konstruktion eines Elektrorollers: Mechatronik-Projekt
- Entwicklung eines RC-Rasenmähers: Mechatronik-Projekt
- Kardangelenke in Lenksystemen: Bachelorarbeit Simulation
- Senkrechtstartendes Modellflugzeug: Bachelorarbeit 3D-Druck
Klassifikation von Bremsgeräuschen mit maschinellem Lernen
Eine sehr interessante Abschlussarbeit unseres Masterstudenten Christian Janorschke (Mechatronik & Produktentwicklung) im Bereich des maschinellen Lernens. Unternehmensseitig war das Unternehmen TMD Friction Holdings GmbH beteiligt, von Hochschulseite wurde die Arbeit von Prof. Stefan Breuer betreut.
Wir wünschen Christian für seine nun folgende Promotion an der Uni Lübeck von Herzen weiterhin so viel Erfolg!
Die Aufgabe
Die Reduktion von Bremsgeräuschen ist ein zentraler Aspekt für die Entwicklung von Bremssystemen für PKWs. Diese Bremsgeräusche entstehen durch verschiedene physikalische Vorgänge und lassen sich anhand ihrer akustischen Ausprägungen voneinander unterscheiden.
Weil die Art der auftretenden Geräusche Rückschlüsse über mögliche Gegenmaßnahmen zulässt, soll ein Programm entwickelt werden, mit dem die aufgezeichneten Geräuschen von (vorerst) Prüfstandtests automatisiert klassifiziert werden können.
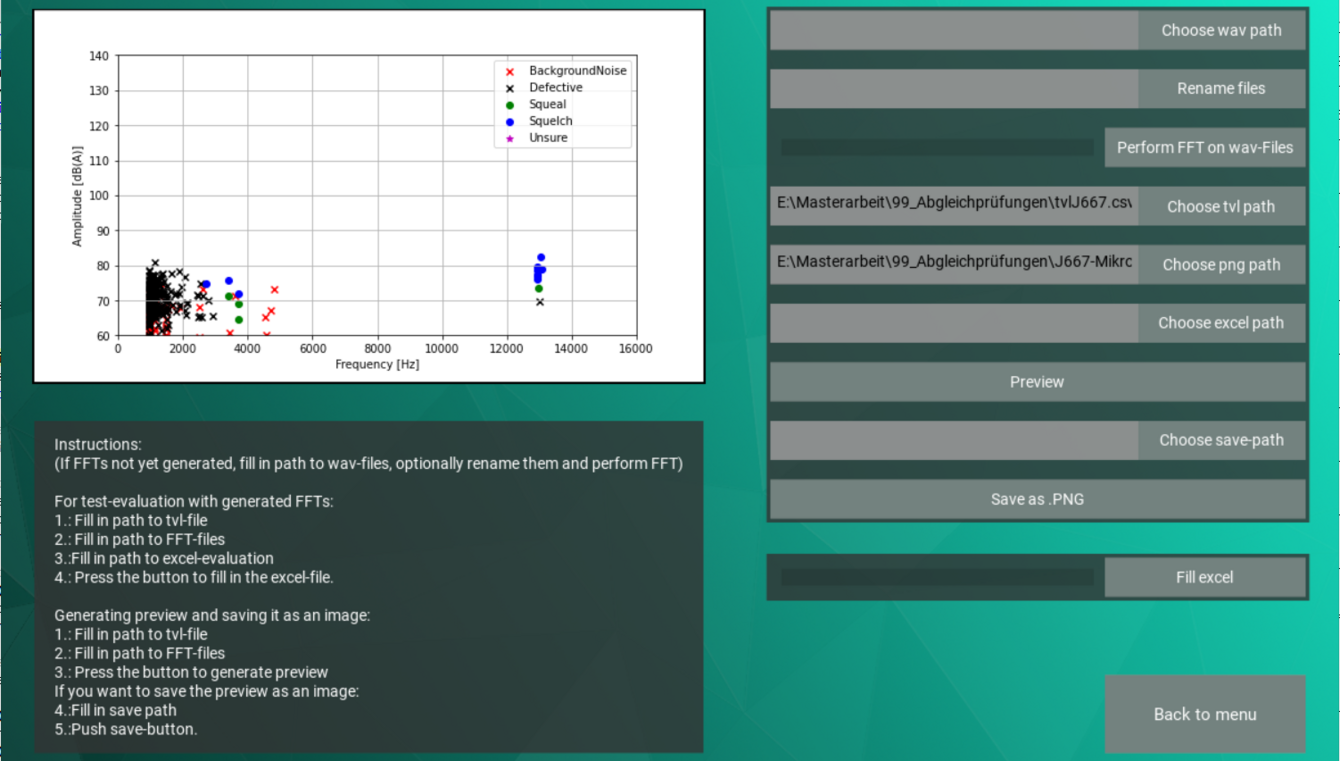
Das Vorgehen
- Neben der Definition und Abgrenzung der einzelnen Klassen von Bremsgeräuschen, für die es aktuell keine Standards gibt, ist für den Einsatz von maschinellem Lernen eine umfangreiche Datenbasis erforderlich.
Eine Teilaufgabe war für Christian dementsprechend zunächst das Sichten und Klassifizieren von Prüfstanddaten. - Anschließend galt es für Christian mithilfe einer Kombination aus Vorverarbeitung und Algorithmen des maschinellen Lernens einen robusten Klassifikator zu entwickeln, der nicht nur auf der vorhandenen Datenbasis sondern auch mit fremden Daten (verschiedene Bremssysteme, Schwungmassen, Prüfprogramme etc.) eine hinreichende Genauigkeit erreicht. Die Schwierigkeit liegt hier in der Vielzahl an möglichen Einflussfaktoren, die zu möglichen Hintergrundeffekten oder Verzerrungen der eigentlichen Geräusche führen können sowie in der unscharfen Trennung der einzelnen Klassen.
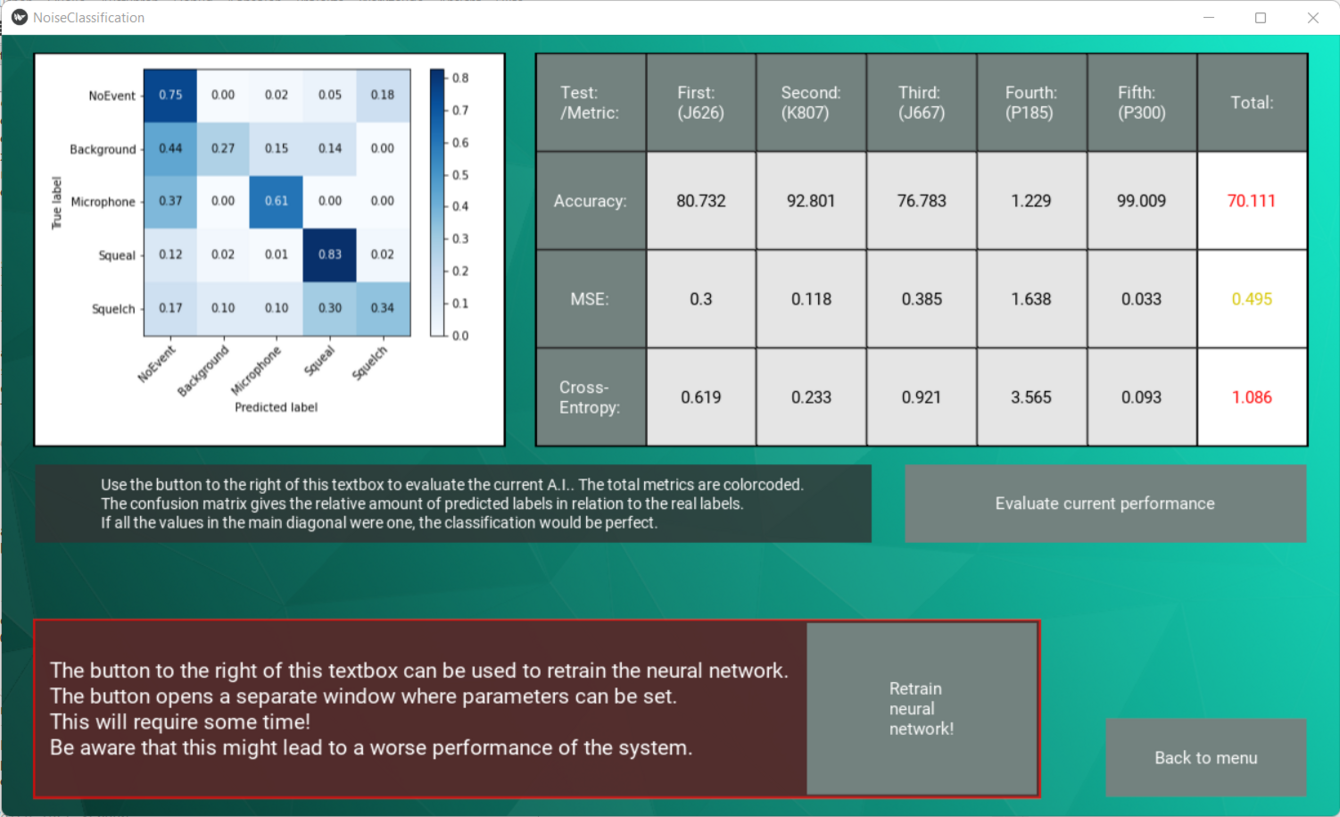
Besondere Herausforderungen und entstandener Mehrwert
Auf Testmengen aus der vorhandenen Datenbasis können vergleichsweise einfach gute Ergebnisse (Genauigkeiten > 98%) erreicht werden. Weil die Datensätze hier teilweise aus denselben Prüfstandtests stammen wie die Lerndaten, werden bekannte Muster wiedererkannt.
Datensätze aus unbekannten Prüfungen können dagegen vollkommen unbekannte Muster aufweisen, die zu ungewollten Tendenzen hinsichtlich der Klassifikation führen. Verschiedene Strategien führen hier zu deutlich verbesserten Ergebnissen ( > 90% statt etwa 70% für fünf beispielhafte, schwierige Prüfungen).
Dennoch können vielseitige Einflussfaktoren zum Versagen der Klassifikation führen, sodass in diesen Fällen die Möglichkeit zum Weiter- oder völlig neuem Anlernen mithilfe zukünftiger Datensätze geschaffen ist. Das von Christian entwickelte Programm wird sich somit zukünftig fortlaufend verbessern und sich auch an neue technische Entwicklungen, Klassen oder sonstige Effekte adaptieren.
Theoretisches Wissen, das besonders relevant war
Physik, Maschinelles Lernen & künstliche Intelligenz, Informatik, Fahrzeugakustik